Fine tune llama2 on Mac
Prepare
-
Download llama2 gguf format model
-
https://huggingface.co/TheBloke/Llama-2-7B-GGUF
-
and put it into “./models/llama-2–7b/”
`ls -lht models/llama-2-7b
total 7997112
-rw-r--r--@ 1 user staff 3.8G Jan 4 13:12 llama-2-7b.Q4_K_M.gguf`
-
- Build the llama.cpp
`git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
make -j`
-
- Prepare the fine tuning data
`mkdir tinystories && cd tinystories
wget https://huggingface.co/datasets/roneneldan/TinyStories/resolve/main/TinyStories_all_data.tar.gz
tar xf TinyStories_all_data.tar.gz`
-
- Then run the fine tune command
`./finetune --model-base ./models/llama-2-7b/ggml-model-q4_0.gguf --train-data tinystories/data49.txt --threads 26 --sample-start "" --ctx 512
./finetune --model-base ./models/llama-2-7b/llama-2-7b.Q4_K_M.gguf --train-data data/allinone.md --threads 26 --sample-start "" --ctx 512`
`./finetune --model-base ./models/llama-2-7b/llama-2-7b.Q4_K_M.gguf --train-data data/allinone.md --threads 26 --sample-start "" --ctx 512
main: seed: 1704345676
main: model base = './models/llama-2-7b/llama-2-7b.Q4_K_M.gguf'
llama_model_loader: loaded meta data with 19 key-value pairs and 291 tensors from ./models/llama-2-7b/llama-2-7b.Q4_K_M.gguf (version GGUF V2)
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.name str = LLaMA v2
llama_model_loader: - kv 2: llama.context_length u32 = 4096
llama_model_loader: - kv 3: llama.embedding_length u32 = 4096
llama_model_loader: - kv 4: llama.block_count u32 = 32
llama_model_loader: - kv 5: llama.feed_forward_length u32 = 11008
llama_model_loader: - kv 6: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 7: llama.attention.head_count u32 = 32
llama_model_loader: - kv 8: llama.attention.head_count_kv u32 = 32
llama_model_loader: - kv 9: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 10: general.file_type u32 = 15
llama_model_loader: - kv 11: tokenizer.ggml.model str = llama
llama_model_loader: - kv 12: tokenizer.ggml.tokens arr[str,32000] = ["", "", "", "", "'
llm_load_print_meta: EOS token = 2 ''
llm_load_print_meta: UNK token = 0 ''
llm_load_print_meta: LF token = 13 ''
llm_load_tensors: ggml ctx size = 0.11 MiB
llm_load_tensors: system memory used = 3891.35 MiB
..................................................................................................
llama_new_context_with_model: n_ctx = 512
llama_new_context_with_model: freq_base = 10000.0
llama_new_context_with_model: freq_scale = 1
llama_new_context_with_model: KV self size = 256.00 MiB, K (f16): 128.00 MiB, V (f16): 128.00 MiB
llama_build_graph: non-view tensors processed: 676/676
llama_new_context_with_model: compute buffer total size = 73.69 MiB
main: init model
print_params: n_vocab : 32000
print_params: n_ctx : 512
print_params: n_embd : 4096
print_params: n_ff : 11008
print_params: n_head : 32
print_params: n_head_kv : 32
print_params: n_layer : 32
print_params: norm_rms_eps : 0.000010
print_params: rope_freq_base : 10000.000000
print_params: rope_freq_scale : 1.000000
print_lora_params: n_rank_attention_norm : 1
print_lora_params: n_rank_wq : 4
print_lora_params: n_rank_wk : 4
print_lora_params: n_rank_wv : 4
print_lora_params: n_rank_wo : 4
print_lora_params: n_rank_ffn_norm : 1
print_lora_params: n_rank_w1 : 4
print_lora_params: n_rank_w2 : 4
print_lora_params: n_rank_w3 : 4
print_lora_params: n_rank_tok_embeddings : 4
print_lora_params: n_rank_norm : 1
print_lora_params: n_rank_output : 4
main: total train_iterations 0
main: seen train_samples 0
main: seen train_tokens 0
main: completed train_epochs 0
main: lora_size = 84863776 bytes (80.9 MB)
main: opt_size = 126593008 bytes (120.7 MB)
main: opt iter 0
main: input_size = 524304416 bytes (500.0 MB)
main: compute_size = 24360536160 bytes (23232.0 MB)
main: evaluation order = LEFT_TO_RIGHT
main: tokenize training data
tokenize_file: warning: sample start pattern '' not found. inserting single sample at data begin
tokenize_file: warning: found 1 samples (max length 30173) that exceed context length of 512. samples will be cut off.
tokenize_file: total number of samples: 1
main: number of training tokens: 30173
main: number of unique tokens: 1460
main: train data seems to have changed. restarting shuffled epoch.
main: begin training
main: work_size = 3329736 bytes (3.2 MB)
train_opt_callback: iter= 0 sample=1/1 sched=0.000000 loss=0.000000 |->
train_opt_callback: reshuffle samples. completed epochs: 1
train_opt_callback: iter= 1 sample=1/1 sched=0.010000 loss=2.079438 dt=00:04:04 eta=17:20:26 |->
train_opt_callback: reshuffle samples. completed epochs: 2`
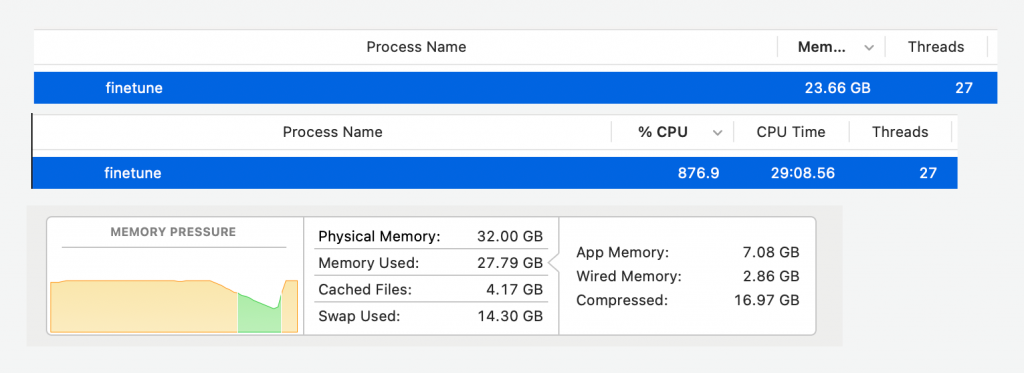
-
- How to run the fine tuned model
` ./main --interactive --model ./models/llama-2-7b/llama-2-7b.Q4_K_M.gguf --lora ggml-lora-LATEST-f32.gguf --prompt"Can you please write a children's story with 200 words about father and son and friendship and bravery?"
`
Reference
-
https://blog.gopenai.com/how-to-fine-tune-llama-2-on-mac-studio-4b42f317c975
-
https://github.com/huggingface/autotrain-advanced